正则表达式(Regular Expression)
重要通知
类目简介
基本概况
- 正则表达式30分钟入门教程:https://www.runoob.com/w3cnote/regular-expression-30-minutes-tutorial.html
- JavaScript RegExp 对象: https://www.runoob.com/js/js-obj-regexp.html
- JavaScript 正则表达式: https://www.runoob.com/js/js-regexp.html
- 正则表达式: https://www.runoob.com/regexp/regexp-tutorial.html
- : https://www.runoob.com/jsref/jsref-obj-regexp.html
- Javascript正则表达式在线测试工具: https://c.runoob.com/front-end/854/
匹配符
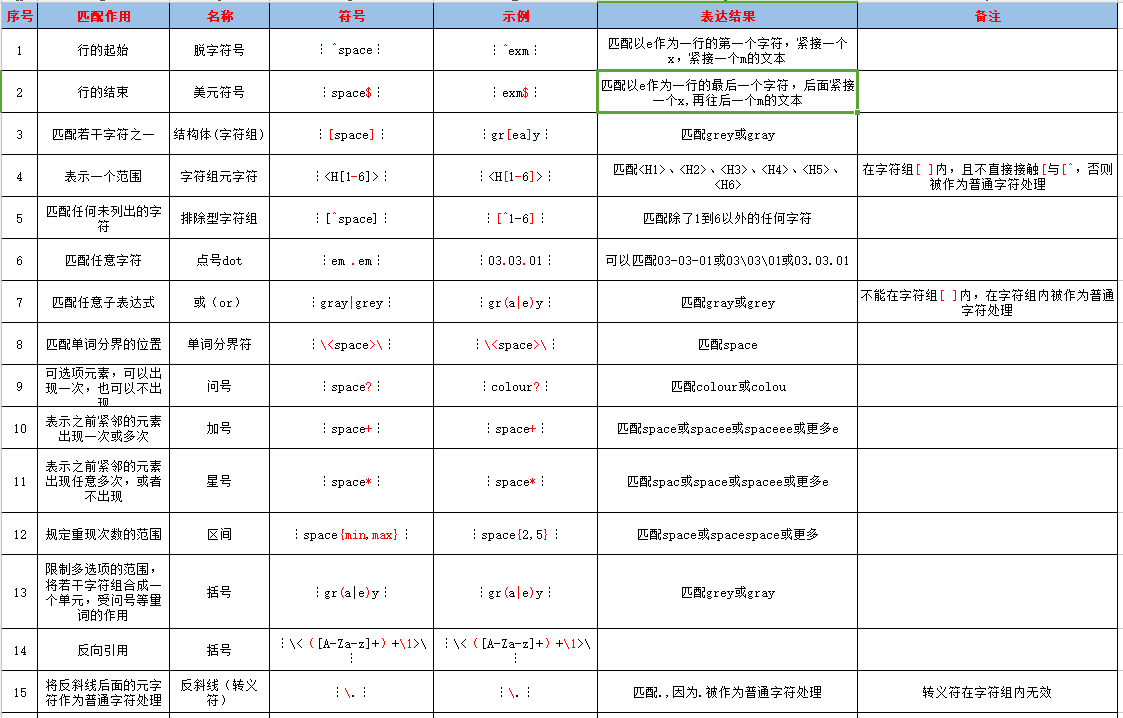
元字符
-----------------------------------------------------------------
# 元字符 描述
-----------------------------------------------------------------
. 查找单个字符,除了换行和行结束符(\n、\r) 使用[\s\S]*替换 注意:\.是代表字符串'.' 而 .*代表任何字符可出现可不出现
\w 查找单词字符
\W 查找非单词字符
\d 查找数字
\D 查找非数字字符
\s 查找空白字符
\S 查找非空白字符
\b 匹配单词边界
\B 匹配非单词边界
\0 查找 NULL 字符
\n 查找换行符
\f 查找换页符
\r 查找回车符
\t 查找制表符
\v 查找垂直制表符
\xxx 查找以八进制数 xxx 规定的字符
\xdd 查找以十六进制数 dd 规定的字符
\uxxxx 查找以十六进制数 xxxx 规定的 Unicode 字符
-----------------------------------------------------------------
基础语法
正则引擎
- DFA()确定性有穷自动机:
- NFA()非确定性有穷自动机:
匹配原理
- 正则式:
- 文本串:
创建对象
修饰符: 修饰符用于执行区分大小写和全局匹配。
- 字面量
/^.../i // 执行对大小写不敏感的匹配
/^.../g // 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止,并返回数组)
/^.../m // 执行多行匹配
- 构造函数
new RegExp(' Regex ', "修饰符");
// 创建正则 动态变量
const regExp = 'https?';
const validater = new RegExp(`^${regExp}`, 'g');
// /^https?:\/\/\w+\.w+/.test()
const content = 'https://test.ysunlight.com/ServerCore/STATIC/files/excel.xlsX';
console.info(validater.test(content));
console.info(content.match(validater));
console.info(content.replace(validater, ''));
正则属性
-------------------------------------------------------------------------------------------------
# 属性 描述
-------------------------------------------------------------------------------------------------
constructor 返回一个函数,该函数是一个创建 RegExp 对象的原型。
global 判断是否设置了 "g" 修饰符
ignoreCase 判断是否设置了 "i" 修饰符
lastIndex 用于规定下次匹配的起始位置
multiline 判断是否设置了 "m" 修饰符
source 返回正则表达式的匹配模式
-------------------------------------------------------------------------------------------------
正则方法
-------------------------------------------------------------------------------------------------
# 方法 描述
-------------------------------------------------------------------------------------------------
compile 在 1.5 版本中已废弃。 编译正则表达式。
exec 检索字符串中指定的值。返回找到的值,并确定其位置。
test 检索字符串中指定的值。返回 true 或 false。
toString 返回正则表达式的字符串。
-------------------------------------------------------------------------------------------------
test()
根据正则条件检索指定内容,返回true | false
let reg = new RegExp("e");
let reg = /^[(a-z)(A-Z)][(a-z)(A-Z)(0-9)]{5,14}$/;
console.log(reg.test('free')); //true
exec()
根据正则条件检索指定内容,返回值是被找到的值,如果没有发现匹配,则返回 null。
let reg = new RegExp("e");
console.log(reg.exec('free')); //e
console.log(reg.exec('ppp')); //null
['', '', index: Number, input: String]
compile()
用于改变 RegExp,既可以改变检索模式,也可以添加或删除第二个参数。
let reg = new RegExp("e");
reg.compile('this');
console.log(reg.compile('free')); //false
表达式
$1$2$3$4$5$6$7$8$9:$1-$9代表着正则表达式从左至右依次9个正则片段匹配,必须对正则条件使用()括号,这样才能匹配$1-$9 经典案例
let str = "这是我的手机号13100000000";
let reg = /(13)(\d)(\d{8})/; //声明正则表达式,该表达式中存在三个匹配,即$1-(13),$2-(\d),$3-(\d{8})
console.log(str.replace(reg, "$1")); //这是我的手机号13
console.log(str.replace(reg, "$1$2")); //这是我的手机号131
console.log(str.replace(reg, "$1$2$3")); //这是我的手机号13100000000
// 示例二
const regCtn = "20230210";
const regExp = /(\d{4})(\d{2})(\d{2})/gi;
console.log(regCtn.replace(regExp, "$1-$2-$3")); // 2023-02-10
量词限定符
指定匹配模式后面的字符必须被匹配,但又不返回这些字符。
正向声明: ?=
- 声明包含在小括号内,它不是分组,因此作为子表达式。
- 匹配模式 (?= 匹配条件) | ?=n 量词匹配任何其后紧接指定字符串 n 的字符串。
const str ="Is this all there is";
console.info(str.match(/is(?= all)/gi)); // [ 'is' ]
console.info(str.match(/th(?=ere)/gi)); // [ 'th' ]
反向声明: ?!
- 与正向声明匹配相反,指定接下来的字符都不必被匹配
- 匹配模式(?! 匹配条件) | ?!n 量词匹配其后没有紧接指定字符串 n 的任何字符串。
const str ="Is this all there is";
console.info(str.match(/is(?! all)/gi)); // [ 'Is', 'is' ]
n+
匹配任何包含至少一个 n 的字符串
n*
匹配任何包含零个或多个 n 的字符串
n?
匹配任何包含零个或一个 n 的字符串
n{x}
匹配包含 x 个 n 的序列的字符串
n{x,y}
匹配包含最少 x 个、最多 y 个 n 的序列的字符串
n{x,}
匹配包含至少 x 个 n 的序列的字符串
禁止引用
反向引用会占用一定的系统资源,在较长的正则表达式中,反向引用会降低匹配速度。如果分组仅仅是为了方便操作,可以禁止反向引用。
(?:pattern)
// ?:断言
console.info('industry'.match(/industr(?:y|ies)/g)); // [ 'industry' ]
console.info('industries'.match(/industr(?:y|ies)/g)); // [ 'industries' ]
const name = 'aaaabbbb';
console.info(name.match(/(a+)(?:b+)/g));
reg=/abc(de|fg)/g
str='abcde12abcfg'
console.log(...str.matchAll(reg)) // ['abcde', 'de'] ['abcfg', 'fg']
reg=/abc(?:de|fg)/g
console.log(...str.matchAll(reg)) // ['abcde'] ['abcfg']
(?<=pattern)
正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。
(?<!pattern)
正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。
分组和捕获
- ( ):用于分组和捕获子表达式。
- (?: ):用于分组但不捕获子表达式。
核心用法
运算符优先级
------------------------------------------------------------------------------------------------------
运算符 描述
------------------------------------------------------------------------------------------------------
\ 转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, \任何元字符、任何字符 定位点和序列(即:位置和顺序)
| 替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。
------------------------------------------------------------------------------------------------------
String对象方法
- search
检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,并返回子串的起始位置。
- match
找到一个或多个正则表达式的匹配。
- replace
用于在字符串中用一些字符串替换另一些字符串,或替换一个与正则表达式匹配的子串。
- split
把字符串分割为字符串数组。
字符串 String
匹配URL
const regExp = /^https?:\/\/www.feierfitness.com[^?]*\?/g;
const regExp1 = /^https?:\/\/www.feierfitness.com[^?]*/g;
const page_url = "https://www.feierfitness.com/";
console.log(page_url?.match(regExp));
// null
console.log(page_url?.match(regExp1));
// ['https://www.feierfitness.com/']
const test_url = 'https://www.feierfitness.com/collections/all';
console.log(test_url?.match(regExp));
// null
console.log(test_url?.match(regExp1));
// ['https://www.feierfitness.com/collections/all']
const url = "https://www.feierfitness.com/collections/power-racks?gad_source=5&gclid=EAIaIQobChMIjO331fbphgMV6BKDAx0NdAgzEAAYASAAEgL6YfD_BwE";
console.log(url?.match(regExp));
// ['https://www.feierfitness.com/collections/power-racks?']
console.log(url?.match(regExp1));
// ['https://www.feierfitness.com/collections/power-racks']
const link = "https://www.feierfitness.com/products/feier-smart-somatosensory-slide-board?https://www.feierfitness.com/products/feier-smart-somatosensory-slide-board&gad_source=5&gclid=EAIaIQobChMIgufE-uLVhgMVeWNHAR0npQhAEAAYASAAEgIyCvD_BwE";
console.log(link?.match(regExp));
// ['https://www.feierfitness.com/products/feier-smart-somatosensory-slide-board?']
console.log(link?.match(regExp1));
// ['https://www.feierfitness.com/products/feier-smart-somatosensory-slide-board']
- js正则去掉"/home/meta/static/output/test.js"的文件名
const inputPath = "/home/meta/static/output/test.js";
// /home/meta/static/output/test.min.js
console.info(inputPath.replace(/\.js/, '.min.js'));
// /home/meta/static/output/
console.info(inputPath.replace(/[^/]+$/, ''));
const validater = /^[a-zA-Z]+$/;
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~]+
特殊需求
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IPv4地址:((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
数字 Number
const validater = /^\d+$/;
const validater = /[0-9]/;
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
let reg = new RegExp("^[0-9]+$");
// 校验金额,精确到2位小数
const regExp = /^[1-9]\d*(?:\.\d{1,2})?$/g;
console.info(regExp.test('01'));
console.info(regExp.test('1'));
console.info(regExp.test('10101.'));
console.info(regExp.test('2900.12'));
console.info(regExp.test('2900.0424'));
var regNum = /^[0-9]*$/
// 附判断数字、浮点的正则表达
/^\d+$/ //非负整数(正整数 + 0)
/^[0-9]*[1-9][0-9]*$/ //正整数
/^((-\\d+)|(0+))$/ //非正整数(负整数 + 0)
/^-[0-9]*[1-9][0-9]*$/ //负整数
/^-?\\d+$/ //整数
/^\\d+(\\.\\d+)?$/ //非负浮点数(正浮点数 + 0)
/^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$/ //正浮点数
/^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$/ //非正浮点数(负浮点数 + 0)
/^(-?\\d+)(\\.\\d+)?$/ //浮点数
//千分位分隔符
async function separateSymbol() {
let text = 7834783.99998;
//JS函数
//小数部分会自动过滤,四舍五入
console.log(text.toLocaleString('en-IN'));
//整数
console.log(text.toString().replace(/(\d{3}[^.])/g, '$1,'));
//整数、小数
let content = text.toString().replace(/\d+/, (n) => {
return n.replace(/(\d)(?=(?:\d{3})+$)/g, '$1,');
});
console.log(content);
}
数字千分位
JS基于正则实现数字千分位用逗号分割 | 参考:'123456789'.replace(/(?!^)(?=(\d{3})+$)/g, ','); 方案一:b.toLocaleString(); 方案二:
var num = 7836493624963274;
var text = num.toString().replace(/(\d)(?=(?:\d{3})+$)/g, '$1,');
console.log(text);
//带小数
let content = text.toString().replace(/\d+/, (n)=> {
return n.replace(/(\d)(?=(?:\d{3})+$)/g, '$1,');
});
console.log(content);
// 数值格式化为千分位
formatter: (v) => `${v}`.replace(/\d{1,3}(?=(\d{3})+$)/g, (s) => `${s},`)
/**
* 数字处理模型
*/
export function transThousandth(content: number | string) {
if ([undefined, null, ''].includes(content as any)) {
return '-'
}
if (!['string', 'number'].includes(typeof content as any)) {
return '-'
}
if (!String(content).trim().length) {
return '-'
}
return String(content).replace(/\d+/, (n) => {
return n.replace(/(\d)(?=(?:\d{3})+$)/g, '$1,')
})
}
典型示例
强制日期格式YYYY-MM-DD
const dateString = "2023.9.5-2023.9.8,2022.3.1,2023.08.07-T,2023.08.01,2023.08.03-2023.08.05,2023.8.7-T,2023.8.1,2023.8.03-2023.08.5";
const firstReg = /\.(\d{1})\.(\d{1})(-|,)/gi;
const secondReg = /\.(\d{1})\./gi;
const thirdReg = /\.(\d{1})$/gi;
// 2023.9.5-2023.9.8,2022.3.1,2023.08.07-T,2023.08.01,2023.08.03-2023.08.05,2023.8.7-T,2023.8.1,2023.8.03-2023.08.5
console.info(dateString);
// 2023.09.05-2023.09.08,2022.03.01,2023.08.07-T,2023.08.01,2023.08.03-2023.08.05,2023.08.07-T,2023.08.01,2023.08.03-2023.08.05
console.info(dateString.replace(firstReg, ".0$1.0$2$3").replace(secondReg, ".0$1.").replace(thirdReg, ".0$1"));
颜色
// 十六进制颜色
const validater = /^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/
// 密码强度,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
const validater = /^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$/;
// 用户名,4到16位(字母,数字,下划线,减号)
var uPattern = /^[a-zA-Z0-9_-]{4,16}$/;
//JS常用String方法
async function jsMethod() {
let content = "hjfg6df76ffdf7_dsf";
//根据正则条件分隔指定内容
console.log(content.split(/\d/)); //[ 'hjfg', 'df', '', 'ffdf', '_dsf' ]
console.log(content.split(/\d/, 2)); //[ 'hjfg', 'df' ]
//根据正则条件替换指定内容
console.log(content.replace(/_/g, '='));
//检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串
//返回匹配的子串,或-1
console.log(content.search(/\d/)); //4
console.log(content.search(/\s/)); //-1
//检索指定内容,若不能检索,则返回null
console.log(content.match(/\d/)); //[ '6', index: 4, input: 'hjfg6df76ffdf7_dsf', groups: undefined ]
}
async function Grammar() {
//根据regExp检索条件校验检测内容,返回true | false
let regNum = /\d/g;
console.log(regNum.test('hsdfg1')); //true
//根据regExp检索条件校验检测内容,返回检测内容或null
let regAddr = /\D/g;
console.log(regAddr.exec('hjghghf6665655sdd')); //[ 'h', index: 0, input: 'hjghghf6665655sdd', groups: undefined ]
//改变regExp检索条件
let regName = /\W/g;
console.log(regName.test('hghgf76fd6f')); //false
console.log(regName.test('?')); //true
regName.compile(/\w/g);
console.log(regName.test('?')); //false
}
async function Modifier() {
//i
console.log(/m/.test('m')); //true
console.log(/m/.test('M')); //false
console.log(/m/i.test('M')); //true
//g
console.log('mm2hsg5sshg'.match(/\d/)); //[ '2', index: 2, input: 'mm2hsg5sshg', groups: undefined ]
console.log('mm2hsg5sshg'.match(/\d/g)); //[ '2', '5' ]
//m
console.log(/conf$/.test('dsfgfjhdsfconffddjshf')); //false
console.log(/conf$/.test('dsfgfjhdsfconf\nfddjshf')); //false
console.log(/conf$/m.test('dsfgfjhdsfconf\nfddjshf')); //true
}
function test() {
let name = 1324365001;
let reg = /(\d)(?=(\d{3})+$)/g;
console.log(name.toString().replace(reg, '$1,'));
}
async function isMatch(str) {
let state = str.match(/({})+/g);
console.log(state);
}
车牌号
const validater = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/;
判断字符是否为中文
const validater = /[\u4E00-\u9FA5]/;
(/[^/u4e00-/u9fa5]/).test(text)
(/^[/u4e00-/u9fa5]+$/).test(text)
(/.*[^/u4e00-/u9fa5]+.*$/).test(text)
(/[^/u4e00-/u9fa5]/).test(text)
(/[^/u4e00-/u9fa5]/).test(text)
设置正则变量
const { path } = this.$route;
// const regFormat = new RegExp("^/" + dx['KINDS_LABEL'] + "", "gim");
// path.match(regFormat)
清除字符串前后的空格
String.prototype.trim = function() {
return this.replace(/(^\s*)|(\s*$)/g, '');
}
校验手机号
// 通用正则
const phoneRegExp = /^((1[3-9]{1}[0-9]{1})+\d{8})$/;
var regCell = /^(((13[0-9]{1})|(14[0-9]{1})|(17[0]{1})|(15[0-3]{1})|(15[5-9]{1})|(18[0-9]{1}))+\d{8})$/;
String.prototype.phone = function() {
let reg = /^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$/;
return '';
}
var reg = /^((13)|(14)|(15)|(16)|(17)|(18)|(19))[0-9]{9}$/;
Email邮箱
// 常用验证,兼容国内外基础邮箱格式
export const regEmailExp = /^[(a-z)|(0-9)|(A-Z)]+.*[(a-z)|_|(0-9)|(A-Z)]*@([(a-z)|(0-9)|(A-Z)]+.)+\.[(a-z)|(A-Z)]{2,}$/;
export function emailValidator(rule: any, value: any, callback: any) {
if (!rule.required) {
return callback();
}
if (value === "") {
callback(new Error("Please input Email"));
} else if (!regEmailExp.exec(value)) {
callback(new Error("Email Format is not corrent!"));
} else {
callback();
}
}
判断字符串是否包含非数字
const value = '100000%';
console.log(/^[0-9]+[0-9]*$/.test(value), value);
中文
let reg = new RegExp("^[\u4e00-\u9fa5]+$");
英文
let reg = new RegExp("^[A-Za-z]+$");
数字、英文、中文
let reg = new RegExp("^[A-Za-z0-9\u4e00-\u9fa5]+$");
校验密码强度
var reg = /^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$/
校验空格
var regNull = /\s/g
校验中文
var regChina = /[\u4e00-\u9fa5]+/g
由数字、26个英文字母或下划线组成的字符串
var regNum = /^\\w+$/
校验身份证号码
var reg = /^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$/ //15位
var reg = /^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$/ //18位
校验日期yyyy-mm-dd
var reg = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|
(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/
判断IE的版本
var reg = /^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$/
货币处理
// 货币单位
const CURRENCY_UNIT = {
USD: '$', //美元
CAD: 'C$', //加拿大元
MXN: 'Mex$', //墨西哥比索
BRL: 'R$', //巴西雷亚尔
EUR: '€', //欧元
GBP: '£', //英镑
SEK: 'Kr', //瑞典克朗
PLN: 'zł', //波兰兹罗提
EGP: '£E', //埃及镑
TRY: '₺', //土耳其里拉
AED: 'د.إ', //阿联酋
INR: '₹', //印度卢比
SGD: 'S$', //新加坡
AUD: 'A$', //澳大利亚元
JPY: 'JP¥', //日元,这里加了JP区别人名币
CNY: '¥' //人名币
}
function CURRENCY_UNIT_LIST() {
const list = Object.entries(CURRENCY_UNIT)
return list.map((item) => {
return {
label: item[0],
value: item[1]
}
})
}
const getCurrencyUnit = function () { return CURRENCY_UNIT };
const currencyUnit = Object.values(getCurrencyUnit());
let currencyRegExp = '';
for (let i = 0; i < currencyUnit.length; i++) {
const currency = currencyUnit[i]
currencyRegExp += '(\\' + currency.split('').join('\\') + ')' + (i < currencyUnit.length - 1 ? '|' : '')
}
const validater = new RegExp(`${currencyRegExp}`, 'g');