数据结构与算法
重要通知
数据机构的精良设计,必须基于不同规模的数据量与数据量的阶段性变化来灵活实现,例如不同规模的数据查询、插入、更新、删除与排序等基本操作,尤其是通过这些操作在时间上的反馈,延迟问题是数据结构所要考虑的重大问题。
基本概况
- 数据结构与算法:https://javabetter.cn/xuexiluxian/algorithm.html
- 数据结构与算法:https://www.runoob.com/data-structures/data-structures-tutorial.html
- 数据结构和算法分析:https://github.com/liuyubobobo/Play-with-Algorithms
计算机公共基础 链接: https://pan.baidu.com/s/1heP2nBhcjUKywL3hW7atmQ 提取码: rfz8 复制这段内容后打开百度网盘手机App,操作更方便哦
数据结构与算法 链接: https://pan.baidu.com/s/1tjegjACyJjTSQnL5Z3wHNw 提取码: g79j 复制这段内容后打开百度网盘手机App,操作更方便哦
数据结构
- 数据集合中各数据元素之间所固有的逻辑关系,即数据的逻辑结构。
- 在对数据进行处理时,各数据元素在计算机中的存储关系,即数据的存储结构。
- 在各种数据结构进行的计算。
算法
算法,即解决问题的操作步骤。
- 算法的基本要素
- 对数据对象的运算和操作。
- 算法的控制结构,即运算或操作间的顺序。
算法复杂度
体现在运行该算法所需要的计算机资源多少,包括时间复杂度与空间复杂度。
时间复杂度
时间复杂度,即执行算法所需要的计算工作量,用大O符号表述。
- O(1):T(n)的上界与输入大小无关,则称其具有常数时间。
- O(n):T(n)的上界与输入大小呈现出线性关系。
- O(n²):
空间复杂度
空间复杂度,即执行这个算法所需要的内存空间,记做S(n) = O(f(n))。
- 输入数据所占的存储空间。
- 程序本身所占的存储空间。
- 算法执行过程中所需要的额外空间。
算法复杂度
概念:运行该算法所需要的计算机资源;
分类:时间复杂度与空间复杂度。
术语
最优(时间复杂度、空间复杂度) 最差(时间复杂度、空间复杂度) 平均(时间复杂度、空间复杂度)
时间复杂度O
O(n):数据量增大几倍,耗时也增大几倍 O(1):最低的时间复杂度,也就是耗时与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。例如:哈希算法 相关表示形式:O(log(N))
空间复杂度
----------------------------------------------------------
符号 名称
----------------------------------------------------------
O(1) 常数
O(log(n)) 对数
O(n) 线性
O(nlog(n)) 线性和对数乘积
O(n²) 平方
O(2^n) 指数
----------------------------------------------------------
常用运算
- 检索:检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。
- 插入:往数据结构中增加新的节点。
- 删除:把指定的结点从数据结构中去掉。
- 更新:改变指定节点的一个或多个字段的值。
- 排序:把节点按某种指定的顺序重新排列。例如递增或递减。
线性表
线性表,即线性结构,是n(n ≥ 0)各数据元素构成的有限序列,表中除第一个元素外的每一个元素,有且只有一个前件,除最后一个元素外,有且只有一个后件。
实现原理
线性表的顺序存储结构
- 存储方式:用物理存储位置上的邻接关系来表示结点间的逻辑关系。
- 优势:适用于小线性表,或者建立之后其中元素不常变动的线性表。
- 不足:不适用于需要经常进行插入和删除运算的线性表和长度较大的线性表。
线性表的链式存储结构
- 存储结点:线性表链式存储结构的基本单位;
- 数据域:存放数据元素本身的信息;
- 指针域:存放一个指向后件结点的指针,即存放下一个数据元素的存储地址;
- 存储方式:每个存储结点都包括数据域和指针域,用指针表示结点间的逻辑关系
线性表的插入运算
- 步骤一:把原来第n个结点至第i个结点依次往后移一个元素位置。
- 步骤二:把新结点放在第i个位置上。
- 步骤三:修正线性表的结点个数。
线性表的删除运算
- 步骤一:把第i个元素之后(不包含第i个元素)的n-1个元素依次前移一个位置。
- 步骤二:修正线性表的结点个数。
代码示例
function Node(element) {
this.element = element;
this.next = null;
}
// 列表对象
function List() {
this.head = new Node("head");
this.find = find;
this.insert = insert;
this.remove = remove;
this.display = display;
this.findPrevious = findPrevious;
}
// 搜索元素方法
function find(item) {
let currNode = this.head;
while(currNode.element !== item) {
currNode = currNode.next;
}
return currNode;
}
// 插入元素方法
function insert(newElement,item) {
let newNode = new Node(newElement);
let current = this.find(item);
if(current === null)
return console.log("can't find the item");
newNode.next = current.next;
current.next = newNode;
}
// 移除元素方法
function remove(item) {
let prevNode = this.findPrevious(item);
if(prevNode.next !== null)
prevNode.next = prevNode.next.next;
}
// 查找item 的前节点
function findPrevious(item) {
let currNode = this.head;
while(currNode.next !== null && currNode.next.element !== item) {
currNode = currNode.next;
}
return currNode;
}
// 显示列表数据
function display() {
let current = this.head;
while(current.next !== null) {
console.log(current.next.element);
current = current.next;
}
}
栈(Stack)
栈是一种
特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作,先进后出,后进先出,另一端是封闭的,既不允许插入元素,也不允许删除元素。
JS实现实现栈
- 代码示例
function Stack() {
this.item = [];
}
Stack.prototype = {
constructor: Stack,
push(element) {
this.item.push(element);
}
pop() {
return this.item.pop();
}
isEmpty() {
return !!this.item.length;
}
size() {
return this.item.length;
}
}
栈内存
自动分配相对固定大小的内存空间,并由系统自动释放。
JS普通数据类型
变量创建时存储在栈内存中。
队列(Queue)
队列和栈类似,也是一种
特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作,先进先出,后进后出。
实现原理
JS实现队列
class Queue {
constructor() {
super();
this.count = 0; //记录队列的数量
this.lowestCount = 0; //记录当前队列顶部的位置
this.items = []; //用来存储元素。
}
// 添加元素
enqueue(element) {
this.items[this.count] = element;
this.count++;
}
// 删除元素(只删除队列头部)
dequeue() {
if(this.isEmpty()){
return 'queue is null';
}
let resulte = this.items[this.lowestCount];
delete this.items[this.lowestCount];
this.lowestCount++;
return resulte;
}
// 查看队列头部元素
peek() {
return this.items[this.lowestCount];
}
// 判断队列是否为空
isEmpty() {
return this.count - this.lowestCount === 0;
}
// 查看队列的长度
size() {
return this.count - this.lowestCount;
}
// 清除队列的元素
clear() {
this.count = 0;
this.lowestCount = 0;
this.items = [];
}
// 查看队列的所有内容
toString() {
if(this.isEmpty()) return "queue is null";
let objString = this.items[this.lowestCount];
for(let i = this.lowestCount+1; i < this.count;i++){
objString = `${objString},${this.items[i]}`;
}
return objString;
}
}
堆(Heap)
堆是一种特殊的树形数据结构,是一个
完全二叉树。堆允许程序在运行时动态地申请某个大小的内存空间。
堆的定义
n个元素的序列{k₁, k₂, kᵢ, ... kₙ}当且仅当满足以下关系时,称之为堆:(kᵢ <= k₂ᵢ, kᵢ <= k₂ᵢ₊₁)或者(kᵢ > k₂ᵢ, kᵢ >= k₂ᵢ₊₁),其中(i = 1, 2, 3, ..., n)。
堆的性质
堆总是满足下列性质
- 堆中某个结点的值总是不大于或不小于其父结点的值;
- 堆总是一棵完全二叉树。
堆内存
堆内存是区别于栈区、全局数据区和代码区的另一个内存区域。堆是动态分配内存,内存大小不固定,也不会自动释放。
JS引用数据类型
变量创建时存储在堆内存中。
JS实现堆
class MaxHeap {
constructor(heap) {
this.heap = heap;
this.heapSize = heap.length;
this.buildMaxHeap();
}
// 构建最大堆
buildMaxHeap() {
for (let i = Math.floor(this.heapSize / 2) - 1; i >= 0; i--) {
this.maxHeapify(i);
}
}
//将以i为根节点的子树调整为最大堆
maxHeapify(index) {
let left = 2 * index + 1;
let right = 2 * index + 2;
let largest = index;
if (left < this.heapSize && this.heap[left] > this.heap[largest]) largest = left;
if (right < this.heapSize && this.heap[right] > this.heap[largest]) largest = right;
if (largest !== index) {
this.swapNum(index, largest);
this.maxHeapify(largest);
}
}
//交换i,j的值
swapNum(i, j) {
let temp = this.heap[i];
this.heap[i] = this.heap[j];
this.heap[j] = temp;
}
//插入一个数
insert(num) {
this.heap.push(num);
this.heap.heapSize = this.heap.length;
let index = this.heap.heapSize - 1;
while (index != -1) {
index = this.shiftUp(index);
}
console.log(this.heap);
}
//删除堆顶元素
pop() {
this.swapNum(0, this.heapSize - 1);
this.heap.pop();
this.heapSize = this.heap.length;
let index = 0;
while (1) {
let temp = this.shiftDown(index);
if (temp === index) break;
else index = temp;
}
}
//堆排序
heapSort() {
while (this.heapSize > 1) {
this.swapNum(0, this.heapSize - 1);
this.heapSize -= 1;
let index = 0;
while (1) {
let temp = this.shiftDown(index);
if (temp === index) break;
else index = temp;
}
}
this.heapSize = this.heap.length;
}
//上浮操作 - 将当前节点与父节点进行比较,如果该节点值大于父节点值,则进行交换。
shiftUp(index) {
let parent = Math.ceil(index / 2) - 1;
if (this.heap[index] > this.heap[parent] && parent >= 0) {
this.swapNum(index, parent);
return parent;
}
return -1;
}
// 下沉操作 - 将当前节点与左右子节点进行比较,如果该节点值不是最大,则进行交换
shiftDown(index) {
let left = Math.floor(index * 2) + 1;
let right = left + 1;
let largest = index;
if (left < this.heapSize && this.heap[left] > this.heap[largest]) largest = left;
if (right < this.heapSize && this.heap[right] > this.heap[largest]) largest = right;
if (largest !== index) {
this.swapNum(index, largest);
}
return largest;
}
}
数组(Array)
数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。
实现原理
链表(Linked List)
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。
实现原理
树(Tree)
树是典型的非线性结构,以分支关系定义的层次结构。
实现原理
- 父结点 (根):在树结构中,每一个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的根结点,简称树的根;
- 子结点和叶子结点:在树结构中,每一个结点可以有多个后件,称为该结点的子结点。没有后件的结点称为叶子结点;
- 度:在树结构中,一个结点所拥有的后件个数称为该结点的度,所有结点中最大的度称为树的度;
- 深度:定义一棵树的根结点所在的层次为1,其他结点所在的层次等于它的父结点所在的层次加1。树的最大层次称为树的深度;
- 子树:在树中,以某结点的一个子结点为根构成的树称为该结点的一棵子树。
- 二叉树:是一个有限的结点集合,该集合或者为空,或者由一个根结点及其两棵互不相交的左、右二叉子树所组成。
- 满二叉树:指除最后一层外,每一层上的所有结点都有两个子结点的二叉树。
- 完全二叉树:指除最后一层外,每一层上的结点数均达到最大值,在最后一层上只缺少右边的若干结点。



图(Graph)
图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。
实现原理
散列表(Hash table)
散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
实现原理
查找技术
查找,就是在某种数据结构中,找出满足指定条件的元素。
顺序查找
二分法查找
使用二分法查找的线性表必须满足两个条件
- 用顺序存储结构
- 线性表是有序表。
排序技术
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
交换类排序法
插入类排序法
选择类排序法
- 简单排序:插入排序、选择排序、冒泡排序(重要)。
- 分治排序:快速排序、归并排序(重要,快速排序还要关注中轴的选取方式)。
- 分配排序:桶排序、基数排序。
- 树状排序:堆排序(重要)。
- 其他:计数排序(重要)、希尔排序。
十大经典排序算法
常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序、桶排序、计数排序等。
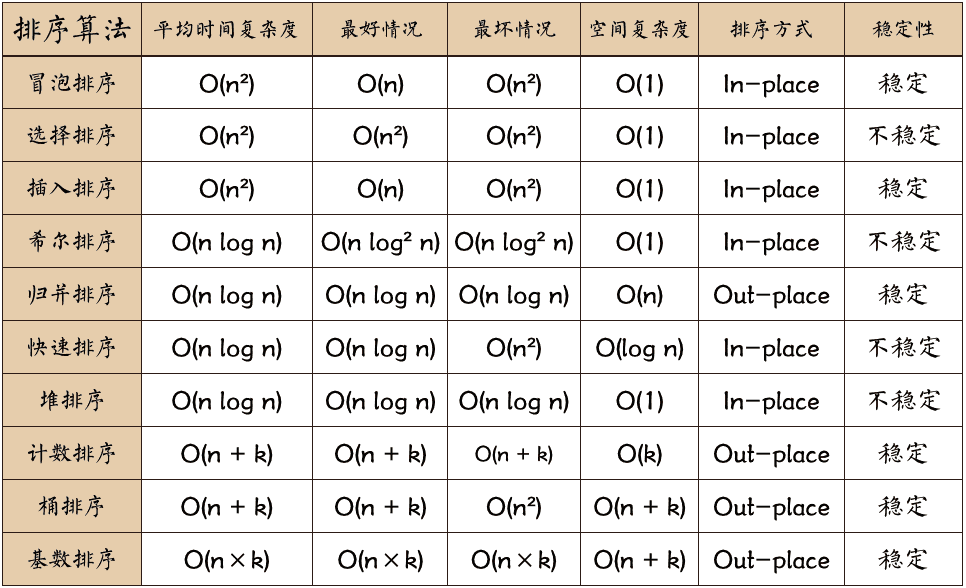
时间复杂度与空间复杂度
- 稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。
- 不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
具体实现过程
 冒泡排序 |  选择排序 |  插入排序 |
 希尔排序 |  归并排序 |  快速排序 |
快速排序
在区间中随机挑选一个元素作基准,将小于基准的元素放在基准之前,大于基准的元素放在基准之后,再分别对小数区与大数区进行排序。
实现原理
function quickSort(array) { // quickSort(array)
// 选择随机数作为基准
const Benchmark = function(array, low, high) {
let pivot = array[low];
while (low < high) {
while (low < high && array[high] > pivot) {
--high;
}
array[low] = array[high];
while (low < high && array[low] <= pivot) {
++low;
}
array[high] = array[low];
}
array[low] = pivot;
return low;
}
// 递归遍历
const recursion = function(array, low, high) {
if (low < high) {
let pivot = Benchmark(array, low, high); // 基准
recursion(array, low, pivot - 1); // 小数区排序
recursion(array, pivot + 1, high); // 大数区排序
}
return array;
}
return recursion(array, 0, array.length - 1);
}
冒泡排序
通过两两相邻数据元素之间的比较和交换,不断地消去逆序,直到所有数据元素有序为止。
实现原理
function reorder(array = []) {
for (let i = 0; i < array.length; i++) {
for (let j = 0; j < array.length - 1 -i; j++) {
if (array[j] > array[j+1]) {
array[j] = array[j] + array[j + 1];
array[j + 1] = array[j] - array[j + 1];
array[j] = array[j] - array[j + 1];
}
}
}
return array;
}
核心算法集
递归算法
递归算法指一种通过重复将问题分解为同类的子问题而解决问题的方法。
实现原理
function recursion(n) {
if (n % 2 == 0) {
console.log(n);
}
if (n > 0) {
return filter(n - 1);
}
}
DFS(深度优先搜索)
深度优先搜索算法(Depth-First-Search),是搜索算法的一种。它沿着树的深度遍历树的节点,尽可能深的搜索树的分 支。当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发 现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
- 深度优先遍历图算法步骤
- 访问顶点v;
- 依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
- 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。上述描述可能比较抽象,举个实例:DFS 在访问图中某一起始顶点 v 后,由 v 出发,访问它的任一邻接顶点 w1;再从 w1 出发,访问与 w1邻 接但还没有访问过的顶点 w2;然后再从 w2 出发,进行类似的访问,… 如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止。
BFS(广度优先搜索)
广度优先搜索算法(Breadth-First-Search),是一种图形搜索算法。BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。如果所有节点均被访问,则算法中止。
- 广度优先遍历图算法步骤
- 首先将根节点放入队列中。
- 从队列中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
- 若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传"找不到目标"。
- 重复步骤2。
Dijkstra算法
迪科斯彻算法使用了广度优先搜索解决非负权有向图的单源最短路径问题,算法最终得到一个最短路径树。
动态规划算法
动态规划(Dynamic programming)是一种在数学、计算机科学和经济学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
实现原理
贪心算法
朴素贝叶斯分类算法
朴素贝叶斯分类算法是一种基于贝叶斯定理的简单概率分类算法。
实现原理
算法题列表
LinkedList
003-从尾到头打印链表 014-链表中倒数第k个结点 015-反转链表 016-合并两个或k个有序链表 025-复杂链表的复制 036-两个链表的第一个公共结点 055-链表中环的入口结点 056-删除链表中重复的结点
Tree
004-重建二叉树 017-树的子结构 018-二叉树的镜像 022-从上往下打印二叉树 023-二叉搜索树的后序遍历序列 024-二叉树中和为某一值的路径 026-二叉搜索树与双向链表 038-二叉树的深度 039-平衡二叉树 057-二叉树的下一个结点 058-对称的二叉树 059-按之字形顺序打印二叉树 060-把二叉树打印成多行 061-序列化二叉树 062-二叉搜索树的第k个结点
Stack & Queue
005-用两个栈实现队列 020-包含min函数的栈 021-栈的压入、弹出序列 044-翻转单词顺序列(栈) 064-滑动窗口的最大值(双端队列)
Heap
029-最小的K个数 Hash Table 034-第一个只出现一次的字符
图
065-矩阵中的路径(BFS) 066-机器人的运动范围(DFS)
斐波那契数列
007-斐波拉契数列 008-跳台阶 009-变态跳台阶 010-矩形覆盖
搜索算法
001-二维数组查找 006-旋转数组的最小数字(二分查找) 037-数字在排序数组中出现的次数(二分查找)
全排列
027-字符串的排列
动态规划
030-连续子数组的最大和 052-正则表达式匹配(我用的暴力)
回溯
065-矩阵中的路径(BFS) 066-机器人的运动范围(DFS)
排序
035-数组中的逆序对(归并排序) 029-最小的K个数(堆排序) 029-最小的K个数(快速排序)
位运算
011-二进制中1的个数 012-数值的整数次方 040-数组中只出现一次的数字
其他算法
002-替换空格 013-调整数组顺序使奇数位于偶数前面 028-数组中出现次数超过一半的数字 031-整数中1出现的次数(从1到n整数中1出现的次数) 032-把数组排成最小的数 033-丑数 041-和为S的连续正数序列(滑动窗口思想) 042-和为S的两个数字(双指针思想) 043-左旋转字符串(矩阵翻转) 046-孩子们的游戏-圆圈中最后剩下的数(约瑟夫环) 051-构建乘积数组
基础算法
笛卡尔乘积
二次贝塞尔曲线
资源
二次贝塞尔曲线在线生成工具:https://www.tweenmax.com.cn/tool/bezier/
简介与核心思想
起点(x0, y0)、控制点(Cx, Cy)、终点(x1, y1)
斐波那契算法
简介与核心思想
斐波那契数列:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n ≥ 3,n ∈ N*) 1 1 2 3 5 8 13 ... F(n)
实现机制
斐波那契搜索就是在二分查找的基础上根据斐波那契数列进行分割的。在斐波那契数列找一个等于略大于查找表中元素个数的数F[n],将原查找表扩展为长度为Fn,完成后进行斐波那契分割,即F[n]个元素分割为前半部分F[n-1]个元素,后半部分F[n-2]个元素,找出要查找的元素在那一部分并递归,直到找到。
推演模型
代码示例
import sys
def fibonacci(n): # 生成器函数 - 斐波那契 a, b, counter = 0, 1, 0 while True: if (counter > n): return yield a a, b = b, a + b counter += 1 f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True: try: print (next(f), end=" ") except StopIteration: sys.exit()
0 1 1 2 3 5 8 13 21 34 55
三次贝塞尔曲线
资源
三次贝塞尔曲线在线生成工具:https://www.tweenmax.com.cn/tool/bezier/
简介与核心思想
起点(x0, y0)、控制点1(Cx1, Cy1)、控制点2(Cx2, Cy2)、终点(x1, y1)
搜索引擎算法
广度优先策略
广度优先遍历(搜索)算法BFS
深度优先策略 深度优先遍历(搜索)算法DFS
http://rapheal.sinaapp.com/2012/08/30/bfs/
查找技术
二分法查找
二分法查找也称拆半查找。
适用条件
用顺序存储结构 线性表是有序表
核心思想
实现步骤
对于长度为n的有序线性表,利用二分法查找元素 X 的过程如下。 将 X 与线性表的中间项比较: ● 如果 X 的值与中间项的值相等,则查找成功,结束查找; ● 如果 X 小于中间项的值,则在线性表的前半部分以二分法继续查找; ● 如果 X 大于中间项的值,则在线性表的后半部分以二分法继续查找。
代码示例
时间复杂度
O(log n):2^O(log n) = n
#时间复杂度
最好情况
1
最坏情况
log2(n)
平均情况
顺序查找
线性表为无序表 (即表中的元素是无序的),则不管是顺序存储,还是链式存储结构,都只能用顺序查找; 即使线性表是有序的,如果采用链式存储结构,也只能用顺序查找。
核心思想
从线性表的第一个元素开始,逐个将线性表中的元素与被查元素进行比较,如果相等,则查找成功,停止查找;若整个线性表扫描完毕,仍未找到与被查元素相等的元素,则表示线性表中没有要查找的元素,查找失败。
实现步骤
代码示例
let array = [8, 10 ,1, 56, 78 ,23, 19]; let count = 78; array.forEach((current, index, target)=> { if (current == count) { console.log(current); return ; } });
#时间复杂度
最好情况
1次:第一个元素就是要查找的元素,则比较次数为1次
最坏情况
n次:最后一个元素才是要找的元素,或者在线性表中,没有要查找的元素,则需要与线性表中所有的元素比较,比较次数为狀次
平均情况
O(n):需要比较 n/2 次。因此查找算法的时间复杂度为O(n)
动态规划算法
回溯
模拟
图计算
极大独立集算法
简介与核心思想
当且仅当对于U 中任意点u 和v所构成的边(u , v) 不是G 的一条边时,U 定义了一个空子图。当且仅当一个子集不被包含在一个更大的点集中时,该点集是图G 的一个独立集(independent set ),同时它也定义了图G 的空子图。最大独立集是具有最大尺寸的独立集。
图的极大独立集在计算机视觉、计算机网络、编码理论和资源配置等领域有着广泛的应用
利用图的分解方法给出了一个求简单无向图所有极大独立集的递归公式.定义了图的邻接矩阵的两个变换和点集合的一些运算
利用二分树给出了一个求无向图的所有极大独立集的有效算法.算法的时间复杂度是O(mn),其中m,n分别是图的所有极大独立集数和顶点个数.算法只需对网络的邻接矩阵进行处理,在计算机上实现起来非常方便.最后,通过实例验证了算法的有效性.
最大独立集其实就是补图的最大团,因为和最大团相反,最大独立集合内的点两两之间都没有边相连。
一个独立集(也称为稳定集)是一个图中一些两两不相邻的顶点的集合。
Bron-Kerbosch算法
算法思想
定义一个图,图中每个顶点表示一个网组。当且仅当两个顶点对应的网组交叉时,它们之间有一条边。所以该图的一个最大独立集对应于非交叉网组的一个最大尺寸的子集。当网组有一个端点在路径顶端,而另一个在底端时,非交叉网组的最大尺寸的子集能在多项式时间(实际上是O(n2))内用动态规划算法得到。当一个网组的端点可能在平面中的任意地方时,不可能有在多项式时间内找到非交叉网组的最大尺寸子集的算法。 首先选择一点为树根,再按照深度优先遍历得到遍历序列,按照所得序列的反向序列的顺序进行贪心,对于一个即不属于支配集也不与支配集中的点相连的点来说,如果他的父节点不属于最大独立集,将其父节点加入到独立集。